We returned to the FPGA Conference Europe in Munich this year with a major update. At our booth, we presented a live demo of DYNANIC running on the brand-new ThunderFjord card from Silicom, equipped with 2×400GE, PCIe Gen5, and the latest Altera Agilex 7 FPGA:






Visitors experienced our fully programmable FPGA packet-processing pipeline, written in HDL and adaptable to the specific requirements of real deployments in AI infrastructure, cybersecurity, and high-performance networking. The feedback confirmed that our approach offers a practical alternative to both rigid ASIC pipelines and overly abstract SmartNIC software stacks.
We were also honored by a visit from Altera representatives, especially Mrs. Deepali Trehan, Altera’s Head of Product Management and Marketing, with whom we discussed possibilities for joint promotional activities. The combination of DYNANIC with cutting-edge Agilex FPGAs creates a compelling and globally unique offering in the SmartNIC space:

In addition to our booth, we were pleased to see that iWave Global, one of our technology partners, also chose to independently demonstrate DYNANIC on their own 100G FPGA hardware platform. This validates our belief that DYNANIC is not tied to any single vendor or board, but rather provides a flexible, vendor-neutral architecture appreciated by multiple FPGA card manufacturers:

Getting 400 Gbps Into the Host? Solved – and Critical.
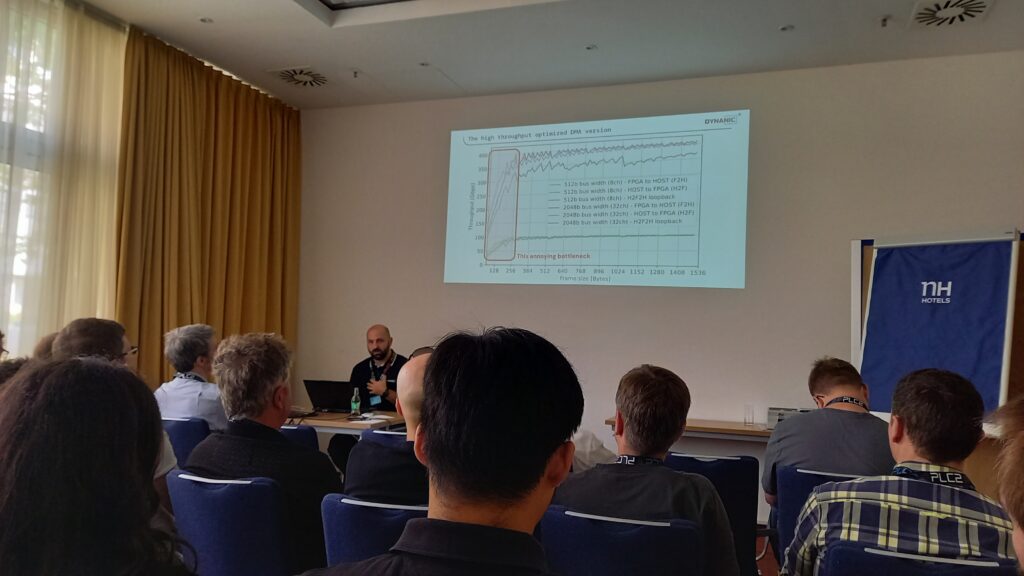
In addition to our live demo, our CTO Lukáš Kekely delivered a technical talk titled:
“How to transfer the shortest packet at sustained 400Gbps over PCIe”
While last year’s presentation focused on what happens inside the 400G-ready FPGA pipeline, this time the topic shifted to a critical and often overlooked part of the data path: transferring high-throughput traffic from the FPGA to the host system over PCIe and DMA.
This isn’t just a performance optimization – for many network applications, such as high-speed intrusion detection, data capture, or low-latency analytics, achieving full-rate host ingress is essential.
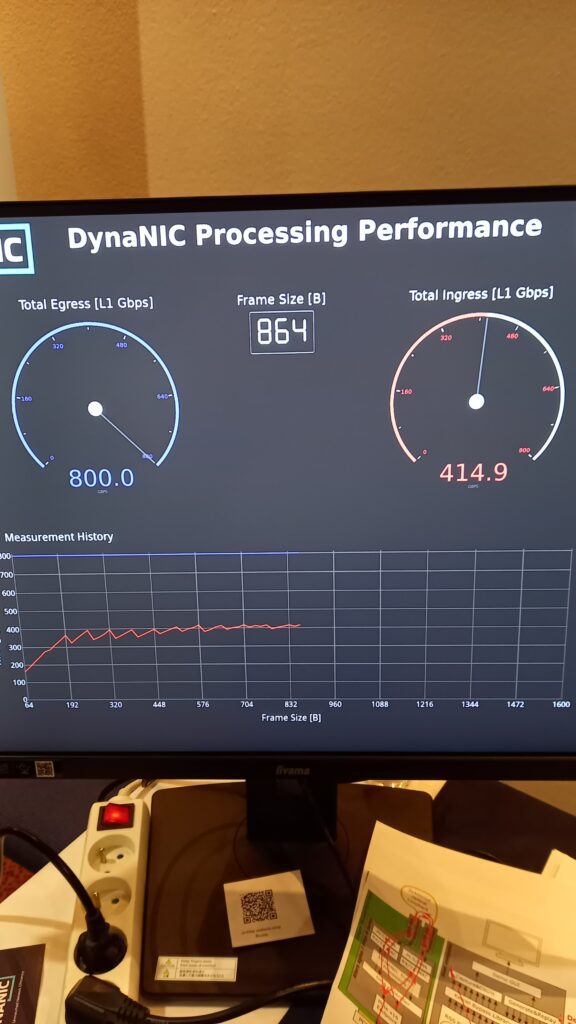
A key challenge arises when handling small packets (e.g., 64–512 byte Ethernet frames), which suffer from high per-packet overhead in the host’s transfer architecture. This can lead to throughput losses of tens of percent, even on modern platforms.
To address this, we presented a simple yet effective method: aggregation of small packets into larger “superpackets” before transmission via DMA. This reduces overhead and allows host software to process traffic more efficiently using standard frameworks like DPDK or XDP.
However, this approach requires coordinated support in both hardware and software. On the FPGA side, the DMA engine must handle smart buffering and packet merging. On the software side, the superpackets must be correctly deaggregated and fed into frameworks without violating memory layout or processing assumptions.
We demonstrated a complete working implementation of this approach on real hardware platforms, along with performance and resource utilization results. The audience response was overwhelmingly positive, with many attendees recognizing the practical value of this architecture in real-world deployments:

➡️ View talk details and abstract
(Presentation slides or will be added soon)
What We Learned
Once again, FPGA Conference Europe confirmed that the market is looking for a flexible, open, and high-performance SmartNIC platform – and this is exactly what DYNANIC delivers.
Whether you are a developer seeking deep access to packet flows, or a systems architect designing scalable 100G+ infrastructure, DYNANIC provides a practical, production-ready solution – proven on multiple hardware platforms.
We thank everyone who visited our booth, attended our session, or shared feedback. We’re excited to continue building partnerships and pushing the boundaries of FPGA-based network acceleration!

